
RTK : couper sa consommation de tokens de 80 % sans changer de workflow
Trente minutes de session Claude Code. Un git diff sur une branche chargée, quelques runs de tests, deux ou trois listings de répertoires. Et au moment où l’agent commence à perdre le fil, on regarde la fenêtre de contexte : 60 % utilisé. Par des sorties de commande.
Ce n’est pas un problème de modèle. C’est un problème de volume. Les outils CLI renvoient des données pensées pour un humain qui lit en diagonale ; un LLM, lui, tokenise tout. Le formatage ANSI, les lignes vides, les warnings répétés, les métadonnées inutiles : chaque caractère compte.
RTK (Rust Token Killer) s’intercale entre le shell et le contexte LLM pour filtrer ce bruit avant qu’il n’y entre. Pas de magie ; de la compression déterministe appliquée à 100+ commandes courantes. Le code source est disponible sur GitHub.
En résumé — RTK réduit de 60 à 90 % les tokens consommés par les sorties CLI dans un workflow IA agentique. Installation en une commande, activation automatique via hook pour Claude Code. Les gains sont réels sur Linux/macOS et WSL ; Windows natif n’a pas de hook, les économies passent par un CLAUDE.md explicite.
Pourquoi les tokens disparaissent-ils si vite dans une session agentique ?
D’après mon expérience, un cargo test qui échoue renvoie couramment entre 400 et 600 lignes. La moitié sont des chemins complets vers des fichiers sources, des numéros de ligne, des stack traces répétées pour chaque assertion ratée. L’agent a besoin de savoir quoi a échoué et où ; il n’a pas besoin des 200 lignes de contexte autour.
Même constat sur git diff : entre les métadonnées de patch, les lignes de contexte non modifiées et les avertissements d’encodage, la partie utile représente, à mon estimation, rarement plus de 30 % de l’output brut. Multiplié par une dizaine d’appels dans une session, c’est une fraction significative du contexte qui disparaît sans apporter de valeur.
Dans mes sessions Claude Code, les sorties de commandes représentent systématiquement entre 40 et 60 % des tokens consommés, alors qu’elles ne portent souvent que 20 à 30 % de l’information utile. C’est le bruit qu’on accepte par défaut parce qu’on n’a pas l’habitude de le mesurer ; aucun outil ne le mesure à notre place.
La compression d’output n’est pas un concept nouveau. Elle est simplement absente des workflows IA agentiques par défaut, parce que ces workflows ont été pensés en termes de fonctionnalités (l’agent peut lire des fichiers, exécuter des commandes) plutôt qu’en termes d’efficacité du contexte.
D’après le README officiel de RTK (version mai 2026), une session Claude Code de 30 minutes consomme environ 118 000 tokens sans RTK ; avec RTK, le même workflow descend à 23 900 tokens, soit une réduction de 80 %.
Pour comprendre comment les agents Claude Code gèrent leur contexte, l’article sur les agents et skills détaille ce que cette architecture change concrètement pour les équipes d’ingénierie.
Comment RTK filtre-t-il les tokens sans perdre l’essentiel ?
RTK réduit en moyenne de 80 % les tokens par sortie de commande en appliquant quatre stratégies complémentaires, sélectionnées selon le type de commande.
Filtrage intelligent : les commentaires, les lignes vides, le formatage ANSI et les métadonnées sans valeur pour un LLM sont supprimés avant transmission. Pour cargo clippy, ça représente jusqu’à 80 % des caractères de l’output brut (README RTK, consulté le 2026-05-16).
Regroupement : les éléments similaires sont agrégés. Au lieu de 15 lignes not found distinctes, RTK renvoie 15 items: not found. Appliqué aux erreurs de build TypeScript ou aux résultats de grep, le gain est immédiat.
Troncature contextuelle : seul le contexte pertinent est conservé. Pour les diffs, RTK ne garde que les blocs modifiés avec une fenêtre de contexte réduite. Pour les tests, seuls les cas en échec sont renvoyés.
Déduplication : les lignes identiques sont comptées et remplacées par une entrée unique avec un compteur. Sur des logs Docker verbeux ou des warnings répétitifs de linter, c’est la stratégie la plus efficace.
Chaque optimisation est spécifique à la commande : RTK traite git diff différemment de docker logs, qui lui-même est traité différemment de pytest. C’est ce qui le distingue d’un simple head -n 100 : les économies sont ciblées, pas brutales.
RTK (Rust Token Killer) est un proxy CLI Rust qui compresse les sorties de commandes shell avant qu’elles n’atteignent le contexte LLM. En appliquant filtrage, regroupement, troncature et déduplication spécifiques à chaque commande, il réduit en moyenne de 80 % les tokens consommés sur une session de développement de 30 minutes, avec un overhead inférieur à 10 ms (README RTK, consulté le 2026-05-16).
Installation et activation en 3 commandes
L’installation dépend de la plateforme, mais dans tous les cas c’est un binaire Rust unique, sans dépendance externe.
Sur macOS et Linux :
# Via Homebrew (recommandé)
brew install rtk
# Via curl
curl -fsSL https://raw.githubusercontent.com/rtk-ai/rtk/refs/heads/master/install.sh | shVérification :
rtk --version
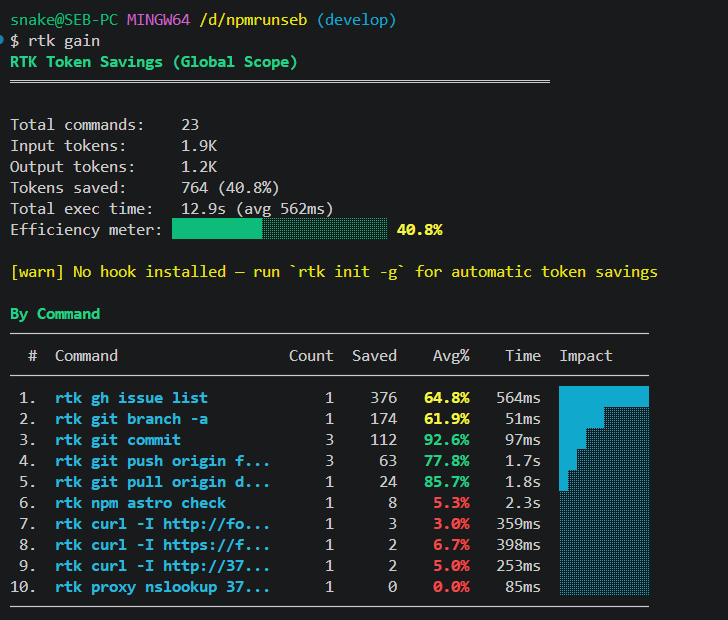
rtk gain # statistiques d'économie accumuléesActivation pour Claude Code :
rtk init -gCette commande installe un hook PreToolUse dans la configuration globale de Claude Code. À partir de là, toutes les commandes Bash passent automatiquement par RTK avant que leur sortie n’atteigne le contexte de l’agent ; zéro changement de workflow requis.
RTK supporte nativement 13 intégrations : Claude Code, Cursor, Gemini CLI, Windsurf, Cline/Roo Code, Kilo Code et plusieurs autres. Chaque agent a sa propre commande d’initialisation :
rtk init -g --copilot # GitHub Copilot
rtk init --agent cursor # Cursor
rtk init --agent cline # Cline/Roo Code
rtk init --agent gemini # Gemini CLISur Windows natif : le hook PreToolUse n’est pas supporté en dehors de WSL. L’alternative est d’ajouter les instructions RTK explicitement dans le CLAUDE.md du projet (rtk init génère un bloc prêt à l’emploi). Les commandes doivent être préfixées manuellement avec rtk ; il n’y a pas d’auto-rewrite.
Combien de tokens économise-t-on vraiment sur une session type ?
Voici les chiffres documentés dans le README de RTK pour une session Claude Code de 30 minutes, basés sur une utilisation typique de chaque commande :
| Commande | Fréquence | Tokens standard | Tokens RTK | Économie |
|---|---|---|---|---|
ls/tree | 10× | 2 000 | 400 | −80 % |
cat/read | 20× | 40 000 | 12 000 | −70 % |
grep/rg | 8× | 16 000 | 3 200 | −80 % |
git status | 10× | 3 000 | 600 | −80 % |
git diff | 5× | 10 000 | 2 500 | −75 % |
cargo test | 5× | 25 000 | 2 500 | −90 % |
pytest | 4× | 8 000 | 800 | −90 % |
| Total | — | 118 000 | 23 900 | −80 % |
Source : README RTK, section “ROI Analysis”, consulté le 2026-05-16.
La ligne avec le plus d’impact dans mon usage quotidien, c’est cat/read : 20 lectures de fichiers dans une session de 30 minutes est une estimation basse pour du travail sur une codebase active. À 40 000 tokens standard contre 12 000 avec RTK, c’est là que se jouent la plupart des économies réelles.
Sur des workflows en mode pay-per-token (Aider, Gemini CLI), des utilisateurs réguliers rapportent des économies de l’ordre de 200 à 500 USD par mois sur leur facture API (README RTK, consulté le 2026-05-16). Sur Claude Code avec des crédits forfaitaires, l’économie se mesure plutôt en sessions plus longues avant saturation du contexte : les tâches complexes qui atteignaient les limites du context window tiennent maintenant jusqu’au bout.
L’overhead est inférieur à 10 ms par commande ; ça ne se perçoit pas en pratique.
Ce que RTK ne couvre pas
RTK opère uniquement sur les sorties de commandes shell. Ce qui arrive dans le contexte via d’autres canaux — fichiers lus directement par l’agent, résultats d’outils MCP, messages utilisateur — n’est pas filtré.
Dans un workflow Claude Code standard, c’est une limitation concrète : les outils natifs Read, Grep et Glob contournent RTK. Pour maximiser les économies, il faut soit privilégier les commandes Bash équivalentes (rtk grep, rtk ls), soit accepter que les outils built-in restent non compressés. Dans mes sessions, j’estime que RTK intercepte environ deux tiers des appels ; le tiers restant passe par les outils natifs.
Autres points à garder en tête :
- Windows natif : pas d’auto-rewrite ; les gains passent par le CLAUDE.md et le préfixe
rtkexplicite. - Compression sans compréhension : sur des sorties de commandes custom ou atypiques, le filtre peut supprimer des lignes qu’un développeur aurait jugées pertinentes.
- Commandes interactives : RTK passe en mode fallback ; le hook ne peut pas compresser ce qu’il ne voit pas encore.
La bonne posture : RTK comme couche d’efficacité, pas comme substitut à une discipline de contexte. Il réduit le volume ; il ne remplace pas le soin apporté à la structuration des tâches.
C’est un levier parmi d’autres dans une stratégie d’outillage cohérente pour une équipe ; RTK s’y intègre sans friction dès lors qu’on a rationalisé son environnement de développement. Combiné à des environnements reproductibles comme les Dev Containers, il contribue à un workflow IA agentique cohérent de bout en bout.
Questions fréquentes
RTK est-il compatible avec tous les shells ?
RTK fonctionne avec bash, zsh, fish et PowerShell. Sur Windows natif, l’auto-rewrite via hook n’est pas disponible : les commandes doivent être préfixées manuellement avec rtk ou les instructions configurées dans le CLAUDE.md du projet. En WSL, le support est complet, hook inclus. La documentation complète est disponible sur rtk-ai.app/guide.
RTK collecte-t-il des données sur mon code ?
Non. La télémétrie est désactivée par défaut et opt-in explicite. Selon le README du projet, RTK ne collecte ni le code source, ni les chemins de fichiers, ni les arguments de commandes, ni aucun contenu sensible. Si la télémétrie est activée, elle se limite à des métriques d’usage agrégées, transmises une fois par jour. La gestion se fait via rtk telemetry enable/disable/forget.
Peut-on exclure certaines commandes du filtrage RTK ?
Oui. Le fichier ~/.config/rtk/config.toml permet d’exclure des commandes spécifiques du hook (exclude_commands = ["curl", "playwright"]). Il est également possible de contourner RTK sur une commande individuelle avec rtk proxy <commande>, qui renvoie l’output brut sans filtrage.
Quel est l’impact sur la vitesse de réponse de l’agent ?
L’overhead de RTK est inférieur à 10 ms par commande, imperceptible en pratique. L’impact perceptible est en fait positif : moins de tokens dans le contexte signifie des réponses plus rapides de la part du modèle. Sur les sessions longues, la différence devient mesurable ; c’est un effet de bord agréable.
Le context window d’un agent IA agentique est une ressource : la comprimer intelligemment avant qu’elle ne soit gaspillée par du bruit de terminal, c’est une décision d’ingénierie, pas un bricolage. RTK automatise une compression que la plupart des développeurs faisaient implicitement à la main, en évitant de coller des outputs bruts dans leurs prompts.
Pour qui code avec des agents au quotidien, c’est une installation de deux minutes. Le retour se voit immédiatement : rtk gain affiche les économies en temps réel, commande par commande.
Pour aller plus loin, l’article sur les agents et skills Claude Code détaille comment tirer parti de la délégation agentique au quotidien.